Automate and optimize your company’s document management
Step 1
Scan / Import

Multiple channels to import your documents, both paper and electronic.
Step 2
Classification
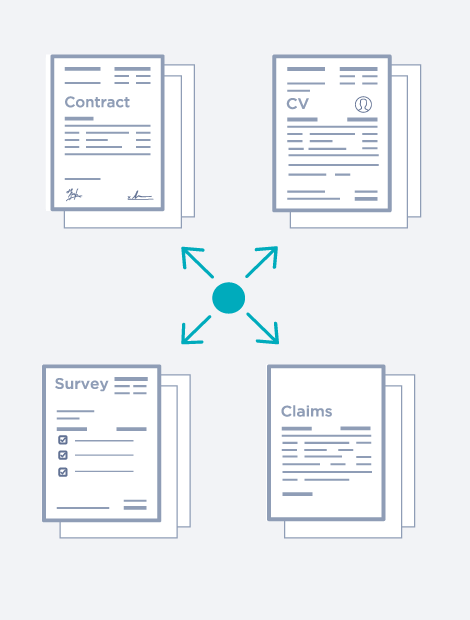
Straightforward configuration, allowing almost unlimited document types.
Step 3
Data extraction
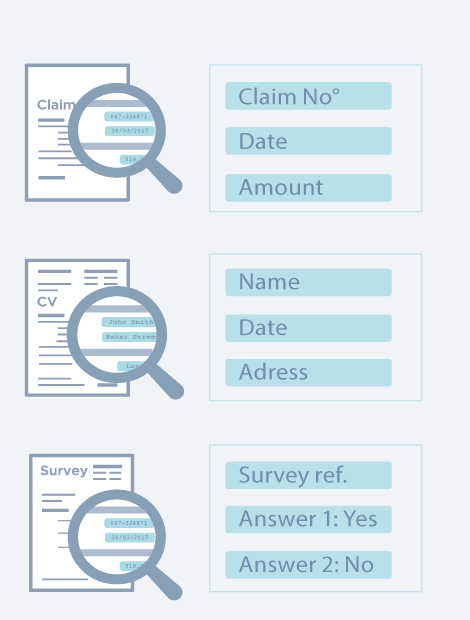
Freeform, template-free extraction. You decide what fields you need per document type.
Step 4
Export

Depending on their type, documents and the data captured are routed to the system of your choice (CRM, ECM, DMS, HR application, archive ...).